Metacat
by James Somers, March 11, 2009
A couple of puzzles
James Marshall's doctoral thesis, "Metacat: a Self-Watching Cognitive Architecture for Analogy-Making and High-Level Perception," produced under the tutelage of Douglas Hofstadter at Indiana University's Fluid Analogies Research Group (FARG), describes a computer program that is capable of solving "string analogy" puzzles like this one:
abc -> abd, ijk -> ?
What's interesting about this particular problem is that the most obvious answer, ijd, doesn't actually occur to most people. We tend to see ijl instead.
The reason (I think) is that we automatically recognize that the letters in each of abc and ijk follow one another in the alphabet, so what sticks out for us is the "1-2-3" pattern. With that in mind, the most natural rule that changes abc to abd is not "replace the last letter by d," but rather something like "increment the last letter." Applying that to ijk gives ijl.
The point of articulating these steps explicitly is to demonstrate that there is a lot of work going on under the hood even when we solve the simplest abstract problems. Work which a computer program like Metacat, and by extension its programmers, have to know how to do precisely if the thing is going to have any chance at tackling these puzzles at a human level. They have to know, for example, how to determine that the most salient feature in the problem above is the relative position of the letters -- and this turns out to be a pretty significant task.
Of course things only get more difficult as the problems get more complex, e.g.,
abc -> abd, mrrjjj -> ?
You may even have to stop for a minute to think about this one. There are several attractive answers, and the "best" one isn't the most obvious.
One possibility is mrrjjk, which follows the same logic as our solution to the first problem. But it loses major points for missing the three "clusters" of identical letters in the target string. Accounting for these gives the much more elegant mrrkkk.
That's not quite optimal, though, because if we look closely we notice that while abc follows the "1-2-3" pattern in terms of alphabet position, mrrjjj does it with letter frequency. So if our rule turns out to be "increment the last letter-group" (accounting again for those clusters), we ought to make sure we "increment" in the appropriate way.
Our best bet, then, is actually mrrjjjj.
Remarkably, Metacat is able to solve this problem and others still more difficult. Perhaps more important, though, is that the method it uses to do this is in some ways just a slowed-down version of our own unconscious cognition, which, Marshall insists, is really all about analogies.
Analogies as the core of thought
These little puzzles may not seem like much. They are, after all, restricted to a highly stylized microdomain: simple manipulations of letter strings. What's so general about that?
Consider, as a parallel example, a set of problems where someone is asked to "complete" an integer sequence, as in:
1, 2, 3, ...
or
1, 1, 2, 3, 5, ...
For a person who (say) knows nothing more about math than the successorship of integers -- pretend that he's even ignorant about simple arithmetical operations like addition -- the task would become an exercise in (a) scouring for relationships among the numbers, and (b) flexibly updating his best hypothesis as he considers more terms. Both of which strike me as exceedingly general abilities.
(Incidentally, there is a program called Seek-Whence out of FARG that tries to complete integer sequences.)
In the same way, Metacat is less concerned with letters than it is with broadly defined structural relationships.
To see how, think of the steps you had to take to solve one of the puzzles above. Your first move, most likely, was to try to discover some "rule" that transforms the original string. Then, either consciously or not, you tried to highlight the relevant abstract structural similarities between the original string and the target string. And finally, you applied your rule to this abstract representation of the target to produce a solution.
The key to the process, and the part most aptly characterized as an "analogy," is the mapping you made between the original and target strings, where you had to see the two different sets of letters as, at some level, playing the same role. Which when you come down to it is exactly what's happening anytime you make an analogy.
If someone were to ask me, for example, who Canada's "president" is, it would be quite natural for me to tell them the name of our prime minister, rather than saying "nobody" -- because in this context prime minister plays roughly the same role as president, namely, head of state, that the person is probably interested in. Similarly, when YouTube pitched themselves as "the Flickr of video," the notion immediately made sense to users, who could easily imagine transforming Flickr's features to incorporate videos instead of pictures.
More mundane analogies pervade everyday life. Our language is full of them: we "spend" time, "retrieve" memories, "get ideas across," and "shoot down" arguments (see Lakoff and Johnson's Metaphors We Live By for more). And even in our basic interactions with objects, we can't help but think laterally instead of literally. Marshall gives the example of eating food off of a frisbee while at a picnic.
Now, in one sense it's somewhat unremarkable to see a frisbee as a plate, but if nothing else it does illustrate the fluidity of our concepts, which for Marshall is pretty much the key to the whole operation. Here's how he characterizes it:
To some extent every concept in the mind consists of a central core idea surrounded by a much larger "halo" of other related concepts. The amount of overlap between different conceptual halos is not rigid and unchangeable but can instead vary according to the situation at hand. Much work has been done in cognitive psychology investigating the nature of the distances between concepts and categories [Shepard, 1962; Tversky, 1977; Smith and Medin, 1981; Goldstone et al., 1991]. For most people, certain concepts lie relatively close to one another in conceptual space, such as the concepts of mother and father (or perhaps mother and parent) while others are farther apart, at least under normal circumstances. However, like the boundaries defining individual concepts, the degree of association between different concepts can change radically under contextual pressure with the potential result that two or more normally quite dissimilar concepts are brought close together, so that they are both perceived as applying equally well to a particular situation, such as when the Earth is seen as an instance of both the mother concept and the planet concept. This phenomenon, referred to in the Copycat model [Metacat's predecessor] as conceptual slippage, is what enables apparently unrelated situations to be perceived as being fundamentally "the same" at a deeper, more abstract level.
What's nice about this view is that it explains apparently ineffable features of the mind, like creativity and insight, as merely special cases of a more general phenomenon. So when Einstein equated acceleration with gravity (and saw gravity as "curved spacetime"), or when Shannon defined information in terms of entropy, they were just exploring unlikely analogies (that ended up being true) -- or, in the above terms, they were "slipping" particularly distant concepts.
What makes such fruitful ideating possible is a kind of "elastic looseness," wherein one's concepts are allowed to range widely enough to combine in novel ways, but still constrained away from nonsense. Lewis Carroll was especially good at toeing that line -- Jabberwocky is wildly imaginative and, at first glance, meaningless, but there is enough structure in there to allow us to translate his made-up words (say, by breaking up the obvious portmanteaus), and "fill in" the plot from context. Most of Dr. Seuss's stuff is the same way: absurd slippage that might be incomprehensible, except that it's packaged in an allegory that even youngsters can swallow.
Analogies, then, appear to be fundamental to every kind of thought, from survival-level object recognition (detecting new threats, for instance) all the way to artistic or scientific innovation. And Metacat is, if nothing else, an attempt to articulate explicitly all of the subcognitive machinery that makes such analogies possible. So, assuming Marshall knew what he was doing, figuring out how Metacat works should be a lot like figuring out how the mind works.
Metacat in action
This is what Metacat looks like at the end of a typical run, after it has found a plausible solution:
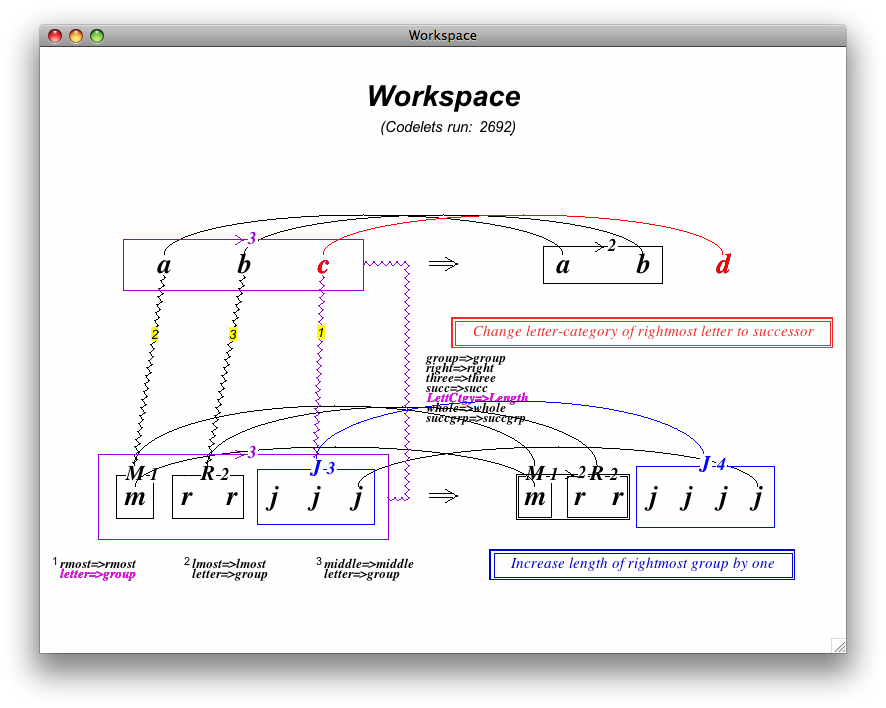
(Notice that the title of the window says "Workspace," which is the name of this particular part of the program. It's only one of many components, but it's probably the most fun to watch, if only because that's where all the conceptual structures get built on top of the strings themselves. Put elsely: if you were working on one of these problems by hand with a piece of paper, you'd probably draw something that looked like the picture above.)
There is a lot going on here. If you look carefully, though, you'll notice that there are really only two "types" of line -- straight and squiggly -- and that together they comprise the three maps we discussed above: (1) from the original string horizontally to its transformed version, (2) from the original string vertically to the target string, and (3) from the target string horizontally to the solution. In addition there are boxes showing the "groups" formed by "bonds" that represent successor/predecessor/sameness relations, short textual descriptions (e.g. "lmost=>lmost") of salient mappings, and natural language explanations of the overarching "rules" that determine how the strings are modified.
It's worth stressing that the horizontal maps are chiefly concerned with differences between the strings, while the vertical map is meant to highlight similarities; this should make sense in light of the discussion above, where we focused on the vertical map as the crux of the analogy -- which is of course more about sameness than differentness.
One may understandably be curious about how all of these Workspace structures are formed. The answer is that a whole slew of computational modules, called "codelets," are sent to the Workspace, one at a time, each with a single low-level task. Here are a few examples (hopefully the names are roughly self-explanatory):
- Bottom-up bond scouts
- Bond builders
- Group evaluators
- Description builders
- Rule scouts
Of course the order in which various codelets are executed, and their relative frequency, effectively determines which part of the solution space is being searched at a given time. Which means that the function for choosing codelets in each step should probably be more sophisticated than a random draw, and should in some sense reflect the actual semantics of the problem at hand.
And they do. What Metacat does is to tie the probability of each codelet's being selected in the next round to the state of the "Slipnet," which is a kind of semantic network containing variously activated "concepts." Here's what it looks like (more active concepts have bigger circles above them):
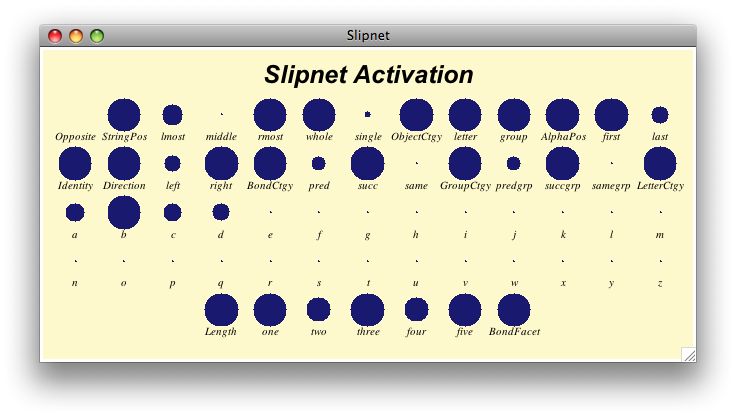
I will leave it to Marshall to describe how this works, and what it means:
In some ways the Slipnet is similar to a traditional semantic network in that it consists of a set of nodes connected by links. Each of these links has an intrinsic length that represents the general degree of association between the linked nodes, with shorter links connecting more strongly associated nodes. [. . .] Each node corresponds to an individual concept, or rather, to the core of an individual concept. A concept is more properly thought of as being represented by a diffuse region in the Slipnet centered on a single node. Nodes connected to the core node by links are included in the central node's "conceptual halo" as a probabilistic function of the link lengths. This allows single nodes to be shared among several different concepts at once, depending on the links involved. Thus, concepts in the Slipnet are not sharply defined: rather, they are inherently blurry, and can overlap to varying degrees.
Unlike traditional semantic networks, however, the Slipnet is a dynamic structure. Nodes in the Slipnet receive frequent infusions of activation as a function of the type of perceptual activity occurring in the Workspace. Activation spreads throughout a node's conceptual halo, flowing across the links emanating from the core node to its neighbors. The amount of spreading activation is mediated by the link lengths, so that more distant nodes receive less activation. However, the link lengths themselves are not necessarily fixed. Some links are labeled by particular Slipnet nodes and may stretch or shrink in accordance with the activation of the label node. A labeled link encodes a specific type of relationship between two concepts, in addition to the conceptual distance separating them. For example, the link between the predecessor and successor nodes is labeled by the opposite node, and the link from the a node to the b node is labeled by the successor node. Whenever a node becomes strongly activated, all links labeled by it shrink. As a result, pairs of concepts connected by these links are brought closer together in the Slipnet, allowing activation to spread more easily between the two, and also making it more likely for conceptual slippages to occur between them.
And,
Whenever new Workspace structures are built, concepts in the Slipnet relating to them receive activation, which then spreads to neighboring concepts. In turn, highly-activated concepts exert top-down pressure on subsequent perceptual processing by promoting the creation of new instances of these concepts in the Workspace. Thus which types of new Workspace structures get built depends strongly on which concepts are relevant (i.e., highly activated) in a given context.
I hope that the correspondence to human cognition is apparent. I am particularly attracted to this idea of a "network of concepts" that (a) directs the activity of lower-level computational/cognitive modules, and then (b) changes shape based on feedback from those modules. It seems to me that when I perceive and think, that is exactly the kind of loop I'm in.
If you have the time (and I assume that if you're reading this sentence, you do), it might be fun to watch a video of all three of these components -- the Workspace, Coderack, and Slipnet -- working together on an actual problem. Watch it here.
You might notice a little thermometer in the top-right corner there. That gives a measure of the "perceptual order in the Workspace": when things are frenzied, and Metacat hasn't settled into any particular "line of thought," it adds more randomness to its codelet selections; but when it starts to hone in on an idea, it "cools off" and eases its way into a conceptual groove, determinedly selecting those codelets most likely to finish the job.
An unfortunate side effect of this otherwise wonderful (and again, psychologically plausible) mechanism is that Metacat risks getting caught in a local optimum, or a "snag," somewhere short of a good solution.
That problem is largely what motivated the idea of a successor to Copycat in the first place. Indeed, what makes Metacat "meta" are a set of self-watching features designed to keep the program out of snags, by (a) watching its own activity in the Workspace and Slipnet so that it can recognize dead ends, and (b) "remembering" particular analogy problems and old solutions, to draw on if it does get stuck.
These meta features show up in the architectural overview that Marshall gives on page 56, which is probably worth taking a look at anyway:
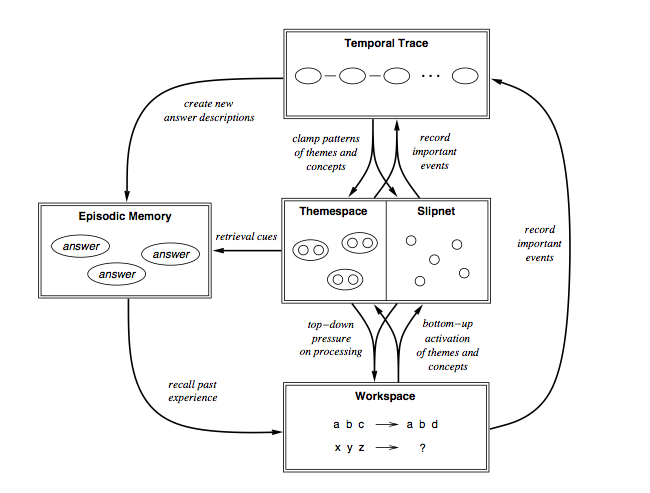
That, in a nutshell, is how Metacat works. It's also probably a good approximation to how your mind works, if not at a neural level than at a conceptual one -- which is probably more interesting, at least for now.
If you'd like to read more, or install the software yourself, or even dive into the tens of thousands of lines of LISP code that makes this run, check out Marshall's project page here: http://science.slc.edu/~jmarshall/metacat/.
Hi James,
I thoroughly enjoyed your piece on MetaCat. I went through a lengthy phase of infatuation with the FARG’s work (which still hasn’t quite ended). I even spent a fair while trying to imagine how I might take their ideas forward, and was absolutely delighted to get the opportunity to present to the group in Bloomington once. I ended up going in a different direction, but I thought I’d share them here with you:
http://www.gregdetre.co.uk/writing/copycat/curiousmachines_analogymaking_copycat.pdf
I’d love to hear your (or anyone else’s) thoughts on them,
Yours, Greg
“That, in a nutshell, is how Metacat works. It’s also probably a good approximation to how your mind works, if not at a neural level than at a conceptual one — which is probably more interesting, at least for now.”
Ha ha… even your post is an analogy.