Exploring the complexity of driving directions
by James Somers, July 28, 2010
When I was planning my first long drive from school in Ann Arbor back home to New Jersey, I remember looking up directions on Google Maps and noticing, as in the results here, that it really doesn't take a lot of steps -- or driving maneuvers -- to get what seems to be a pretty long way across the country. In fact it only requires seventeen turns using the route Google gives, and even that number is inflated (those "keep left" and "keep right" steps are helpful, maybe, but not necessary).
Just for fun, I tried comparing that 500+ mile trip to one a fraction of its size, something closer to ten miles. You can see such a route here.
Remarkably, at only 2% of the distance, this short hop from one small town in New Jersey to another requires just fifteen steps, or only two fewer than the hefty road trip to Michigan.
I began to wonder: what's the relationship between the length of a road trip and the complexity of the route? Do most trips, long or short, require roughly the same number of steps? How many steps are there in the most complex route in the country? What's the distribution of step counts for every possible route in the contiguous United States?
These questions turn out to be tractable, thanks in large part to Google's Directions API, which gives lowly developers like me access to their full suite of mapping, geolocation, and pathfinding algorithms, huge stores of data, and fast servers that can deliver tens of thousands of query results to a single client computer in a matter of minutes.
Before we dive into methods and results, though, let's lay out exactly what we're looking for:
We want a histogram of step counts for some representative sample of routes within the US. This will give us a really good sense of how complex a typical road trip might be.
We'd like to find the most complex route in the country, i.e., a pair of points such that the driving directions between them, given by Google, include a larger number of steps than for any other pair in the contiguous US. It's extremely unlikely that we'll find the monster route, but at least we'd like a ballpark estimate of its step count -- is it 35, 500, 90, 180?
We want a plot of route distance against route complexity. What will the plot look like? Is complexity a linear function of distance? Is there a direct or inverse relationship? Will there be any pattern at all?
It would be pretty cool to find a "coefficient of friction" for regions in America, that is, a numerical estimate of how hard it is to drive through a particular region based on how many steps there are, on average, in a route passing through it. We could use this information to create a "heat map" of the entire US, with individual counties or zip codes shaded by friction. Such a map would help us figure out which states have the thorniest roads, or where the most straightforward routes are, or which cities are the hardest to get out of.
To get started, then, I went looking for a random sample of points. One way to do that would be to draw a box inscribed within the continental US and simply generate random lat-longs within that box. The trouble with that method, I thought, was that it could easily drop you in barren or ridiculous places like deserts or lakes; I wanted to focus on plausible real-life trips from one population center to another.
So I went looking for a data set, and before long, found one: the "MaxMind World Cities with Population" file, a 33 MB free download with more than enough data to get things rolling: after eliminating non-U.S. cities (a simple grep did the trick, since the text is nicely structured), I was left with 141,989 points covering nearly every corner of the country.
I hacked together a tiny Rails project (RoR being my hammer-that-makes-everything-look-like-a-nail at the moment) to (a) load the cities and lat-longs into some structured form, (b) drop that data into an HTML page hooked up to the JavaScript Google Directions API, and (c) write the results back to a database. All of the relevant code, along with a SQLite3 database with the structured cities data and results, is available at this github project page.
Perhaps the most important snippet, which I'll excerpt below, is the code that actually samples points and talks to Google:
var map;
var directionDisplay;
var directionsService;
var stepDisplay;
var markerArray = [];
var step_counts = [];
var step_summaries = [];
function initialize() {
// Instantiate a directions service.
directionsService = new google.maps.DirectionsService();
}
function calcRoute(start, end) {
// Retrieve the start and end locations and create
// a DirectionsRequest using DRIVING directions.
var city_start = [start[2], start[3]].join(", ");
var city_end = [end[2], end[3]].join(", ");
var latlong_start = [start[0], start[1]].join(",");
var latlong_end = [end[0], end[1]].join(",");
var request = {
origin: latlong_start,
destination: latlong_end,
travelMode: google.maps.DirectionsTravelMode.DRIVING
};
// Route the directions and pass the response to a
// function to count the number of returned steps.
directionsService.route(request, function(response, status) {
if (status == google.maps.DirectionsStatus.OK) {
var step_ct = countSteps(response);
step_counts.push(step_ct);
step_summaries.push([step_ct, city_start, city_end])
} else {
console.warn("Couldn't count steps for this route.");
}
});
}
function countSteps(directionResult) {
var myRoute = directionResult.routes[0].legs[0];
return myRoute.steps.length;
}
function getAndExecutePairs(n) {
$.get("/directions/get_pairs", {n: n},
function(ret) {
pairs = ret;
console.log(n + " lat/long pairs downloaded successfully.");
execute(pairs);
}
)
}
function execute(pairs) {
for (i = 0; i < pairs.length; i++) {
pair = pairs[i];
start = pair[0];
end = pair[1];
calcRoute(start, end);
}
}
It's all pretty straightforward. The process is kicked off by the getAndExecutePairs() function, which just hits the Rails server for n pairs of cities. This is the code it calls:
def get_pairs
n = params[:n].to_i
cities = City.find(:all, :limit => n * 2, :order => "random()");
lat_longs = cities.collect {|c| [c.latitude, c.longitude, c.city, c.state]}
pairs = Hash[*lat_longs].to_a
render :json => pairs
end
And that's it. With just ~100 or so lines of code, I was able to get a decent grip on the first three of the four questions posed above. In particular:
1. What's the distribution of step counts for every possible route in the contiguous United States?
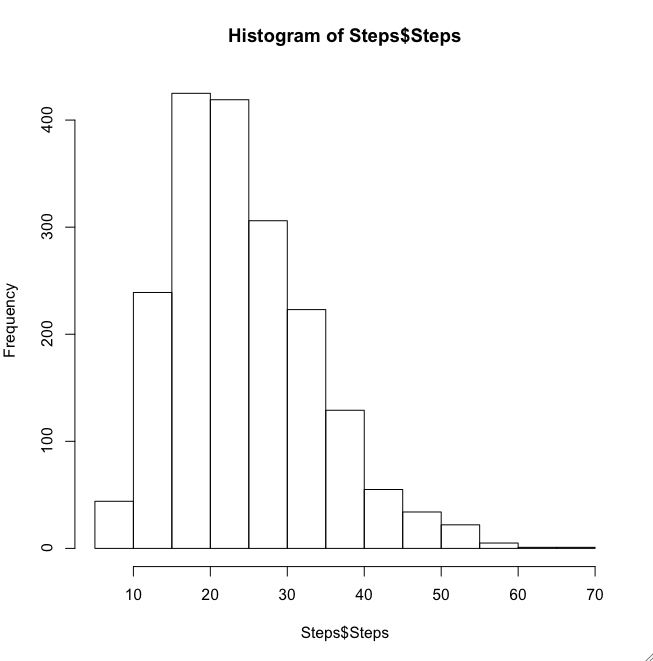
The answer, based on a random sample of some 2,000 points (and confirmed later by 8,000 more trials), is that you have a sort of right-skewed distribution centered at 20-30 steps and tailing out near 60.
2. How many steps are there in the most complex route in the country?
This is a lot less definitive, but the answer I got was 69 steps, in a route from Ponderose Pine, NM to Wildwood, MN. A friend suggested something like the following approach for finding more complicated routes:
Suppose you're getting "good" (i.e., stepful) routes between points A and B. Draw a box around each of A and B and "wiggle" your start points within that box. If wiggling in one direction removes steps, try wiggling in another direction; or if it's not direction that matters, but rather something tricky like "being within a development or behind a river," maybe you could just select points within the box randomly and assign scores to different areas (sort of like a game of Battleship). That way you slowly optimize promising routes until you end up with truly high numbers.
One potential pitfall of this approach is that there could be discontinuities -- A to B could take an unremarkable 35 steps, but (A + ε) to B could take 70 steps -- in which case you might not choose the right starting points to begin with. But this would probably only happen if there was something like a maze next to a normal neighborhood.
3. What's the relationship between trip distance and route complexity?
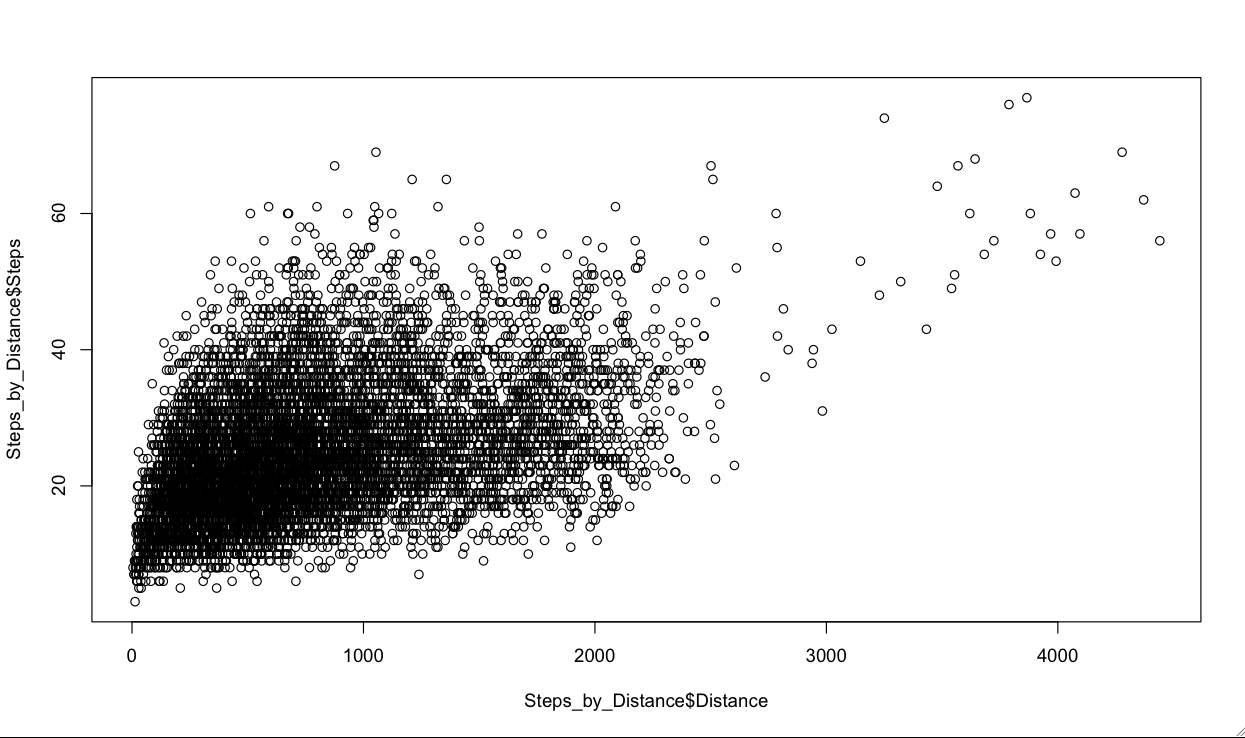
The graph above plots route distance (measured as the surface distance between the two lat-long pairs) against step counts. Aside from a few outliers, you'll notice that a really wide range of step counts is covered by a relatively narrow range of distances: that is, most of the variation in step counts is accounted for in trips less than a few hundred miles; and at the margin, an extra mile buys you very little in terms of route complexity.
Perhaps the most interesting points are those short routes with a large number of steps. See, for example, the 69-step route called out above (just over 1,000 miles), or the 67-step route from South Lyndeborough, NH to Hartley, GA (875 miles).
(You'll notice a few routes with more than 70 steps -- these can be safely ignored, since they either originate from or end up in Alaska (oops!)).
4. Can you generate a "heat map" that shades regions by their "coefficient of friction," i.e., a numerical estimate of how hard it is to drive through a particular region based on how many steps there are, on average, in a route passing through it?
This is left as an exercise for the reader, as is the task of finding even longer routes (here's a 75-stepper) and the more general underlying problem of understanding which features -- of cities and roads and geography -- are implicated in route complexity.
Really interesting. You would think, instinctively, that most steps are accounted for in local settings; once you’re on the highway, you’re just cruising until you get off. I wonder, just to prove that, could you somehow compare the difference in steps of trips that a) start near a highway, b) end near a highway and c) both.
I had the exact same response as Chip’s: the steps are going to be (almost all) at either end of the journey. For the US, at least, the amount of highway between the ends will make no difference.
It would simplify the problem to fix one of the end-points as somewhere ON a highway in about the center of the country, then search for start points that create the most complicated journey to that end.